AI 入门问题大全,人工智能基础知识
一、通识相关问题
1、什么是人工智能?
2、什么是 AIGC?
3、大学人工智能专业学啥?
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
4、AI 会不会取代人类的工作?
5、什么是 AGI?
6、什么是人工智能算法?
7、什么是提示词?
8、什么是图灵测试?
9、什么是 Agent?
10、什么是 AIoT?
11、什么是 GPT?
12、人工智能有哪些常用的开发语言?
13、如何判断机器是否是人工智能?
14、哪些行业正在使用 AI?
15、普通人如何让 AI 融入到学习当中?
16、普通人如何让 AI 融入到工作当中?
1.
2.
3.
4.
5.
6.
7.
8.
17、普通人如何跟上 AI 的发展步伐?
18、什么是 AI 套壳网站?
19、学习了 AI 应该怎么赚钱?
1.
2.
3.
4.
5.
6.
7.
20、学习 AI 可以从事哪些工作?
1.
◦
◦
2.
◦
◦
3.
◦
◦
4.
◦
◦
5.
◦
◦
6.
◦
◦
7.
◦
◦
8.
◦
◦
21、什么是 AI 数字人?
22、AI 入门学习有没有什么书单推荐?
23、当前阶段 AI 发展到什么阶段了?
24、未来 AI 发展趋势是什么?
25、为什么国外的很多 AI 工具需要特殊上网?
二、模型相关问题
1、什么是大语言模型?
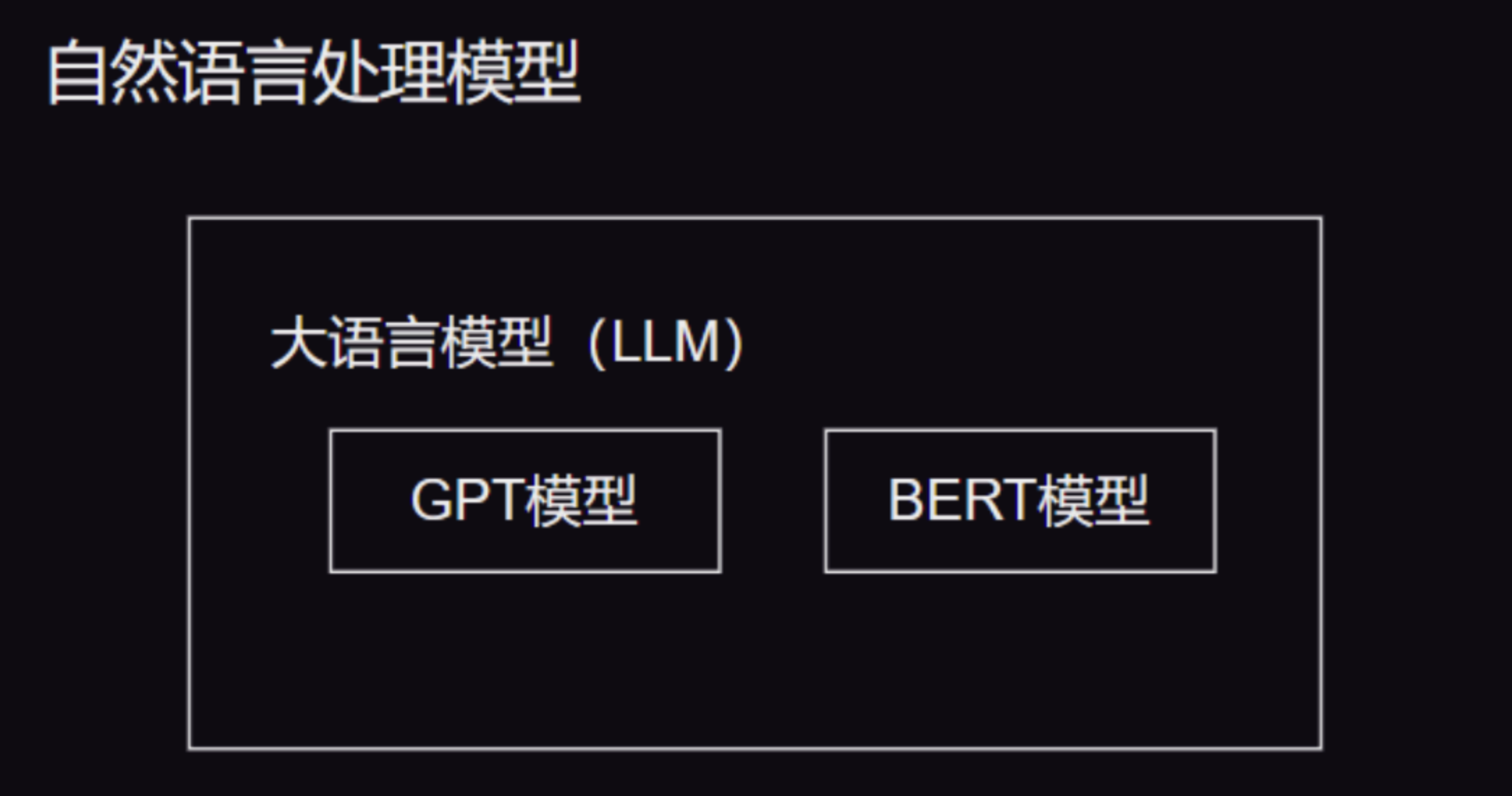
2、什么是模型微调?
3、什么是模型参数?
4、什么是多模态模型?
5、什么是扩散模型?
6、什么是语言模型里的 token?
7、什么是开源大模型?
8、什么是提示工程?
9、什么是 BERT?
10、什么是 Checkpoint?
11、什么是语料库?
1.
2.
3.
4.
5.
12、什么是大模型的训练?
13、什么是大模型的推理?
14、为什么 AI 训练需要数据标注?
15、为什么 AI 训练需要耗费大量电力?
三、机器学习问题
1、什么是机器学习?
1.
2.
3.
4.
5.
6.
7.
2、什么是深度学习?
3、什么是 Transformer?
3、什么是 NLP?
4、什么是预训练?
5、什么是 GAN?
6、什么是卷神经网络?
7、什么是人工智能里的无监督学习?
8、什么是 AML?
9、什么是 AutoML?
10、人工智能、机器学习、深度学习三者之间的关系?
11、什么是监督学习?
12、什么是神经网络?
四、技术相关名词
1、什么是 ASR?
2、什么是 TTS?
3、什么是 CV?
4、什么是 Chatbot?
5、什么是 Encoder?
6、什么是 Decoder?
五、AI 绘画问题
1、什么是 AI 绘画里面的“抽卡”?
2、什么是 AI 绘画里面的 ControlNet ?
3、什么是 AI 绘画里面的“炼丹”?
4、什么是 AI 绘画里面的“咒语”或者“关键词”?
5、AI 绘画里面的“Lora”是指什么?
6、什么是 DALL-E?
7、AI 绘画里面的 Seed 是指什么?
8、AI 绘画的主要参数有哪些?
1.
2.
3.
4.
5.
6.
7.
9、AI 绘画出现了还需不需要学美术基础?
10、AI 绘画只有专业的人才能学习吗?
六、硬件相关问题
1、什么是 GPU?
2、什么是TPU?
3、什么是 FPGA?
4、什么是 ASIC?
5、国内有哪些比较大的人工智能芯片公司?
6、国外有哪些比较大的人工智能芯片公司?