一文读懂:大模型的思维链 CoT(Chain of Thought)
前言:
思维链,在人工智能领域,是一个非常非常新的概念。强大的逻辑推理是大语言模型“智能涌现”出的核心能力之一,好像AI有了人的意识一样。而推理能力的关键在于——思维链(Chain of Thought,CoT)。
对于复杂问题(尤其是复杂的数学题),大模型很难直接给出正确答案。COT通过要求/提示模型在输出最终答案之前,显式输出中间逐步的推理步骤这一方法来增强大模型的算数、常识和推理的性能。cot方法简单,且有效。
CoT 大幅度提高了 LLM 在复杂推理任务上的性能,并且输出的中间步骤方便使用者了解模型的思考过程,提高了大模型推理的可解释性。目前,思维链推理已经成为大模型处理复杂任务的一个常用手段
本文部分结合了 爱吃牛油果的璐璐 、 夕小瑶和绝密伏击的文章内容,展开讨论 CoT的诸多概念的介绍:
1. 什么是思维链 CoT ?
关键概念介绍
在介绍什么是思维链 CoT 之前,让我们先从两个更大的概念开始。
首先,什么是“语言智能”?语言智能可以被理解为“使用基于自然语言的概念对经验事物进行‘理解’以及在概念之间进行‘推理’的能力”,无疑,人类是目前已知生物之中唯一具备这种高级的抽象与理解能力的,从另一个层面而言,语言智能能力也是将人类从动物之中区分出来作为一种“智慧物种”的标志能力之一。

而随着参数量的飞升,以 Transformer 为基础架构的大规模语言模型以 “Chat” 的方式逐渐向人们展现出了它的概念理解与概念推理的能力。直观上,作为“语言模型”的大模型具备概念理解能力并不难理解,但是仅仅像 Word2vec 一样只能得到“国王”与“男人”的“距离”更近的结论对于语言智能而言必然远远不够。
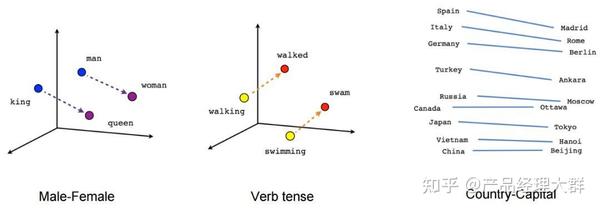
真正让大模型逼近“语言智能”,在于大模型展现出的概念推理能力。推理,一般指根据几个已知的前提推导得出新的结论的过程,区别于理解,推理一般是一个“多步骤”的过程,推理的过程可以形成非常必要的“中间概念”,这些中间概念将辅助复杂问题的求解。

思维链
2022 年,在 Google 发布的论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中首次提出,通过让大模型逐步参与将一个复杂问题分解为一步一步的子问题并依次进行求解的过程可以显著提升大模型的性能。而这一系列推理的中间步骤就被称为思维链(Chain of Thought)。
区别于传统的 Prompt 从输入直接到输出的映射 <input——>output> 的方式,CoT 完成了从输入到思维链再到输出的映射,即 <input——>reasoning chain——>output>。如果将使用 CoT 的 Prompt 进行分解,可以更加详细的观察到 CoT 的工作流程。

如上图所示,一个完整的包含 CoT 的 Prompt 往往由指令(Instruction),逻辑依据(Rationale),示例(Exemplars)三部分组成。一般而言指令用于描述问题并且告知大模型的输出格式,逻辑依据即指 CoT 的中间推理过程,可以包含问题的解决方案、中间推理步骤以及与问题相关的任何外部知识,而示例则指以少样本的方式为大模型提供输入输出对的基本格式,每一个示例都包含:问题,推理过程与答案。
以是否包含示例为区分,可以将 CoT 分为 Zero-Shot-CoT 与 Few-Shot-CoT,在上图中,Zero-Shot-CoT 不添加示例而仅仅在指令中添加一行经典的“Let’s think step by step”,就可以“唤醒”大模型的推理能力。而 Few-Shot-Cot 则在示例中详细描述了“解题步骤”,让模型照猫画虎得到推理能力。
2. CoT 的作用
1、COT原则上允许模型把一个复杂问题拆解成多个步骤,也就是说需要更多推理步骤的问题可以多分点计算量
2、COT提供了一个观察模型为何会犯错的窗口,因此也就提供了一个debug模型的机会
3、COT能用在数学应用题、常识推理和符号操作上,也就有可能用在任何人类通过语言能解决的问题上
4、COT非常好用,任何语言模型都可以用,加在 few-shot的样例中就能生效。省去了重新训练模型的功夫。
大模型的逻辑推理能力提升
谷歌之前在大模型下了很大功夫,GPT 生成式预训练模型中的“T”,也就是 Transformer,就是谷歌大脑搞出来的。但是,预训练 + 精调的大模型搞了几年,仍然没办法很好地完成多步骤推理任务,比如数学问题和常识推理。
所以 Jason Wei 等人提出了思维链提示的方法,真的一下子就让大模型的逻辑推理能力不一样了。
具体来说,有三个不一样:
- 常识推理能力赶超人类。以前的语言模型,在很多挑战性任务上都达不到人类水平,而采用思维链提示的大语言模型,在 Bench Hard(BBH) 评测基准的 23 个任务中,有 17 个任务的表现都优于人类基线。比如常识推理中会包括对身体和互动的理解,而在运动理解 sports understanding 方面,思维链的表现就超过了运动爱好者(95% vs 84%)。
- 数学逻辑推理大幅提升。一般来说,语言模型在算术推理任务上的表现不太好,而应用了思维链之后,大语言模型的逻辑推理能力突飞猛进。MultiArith 和 GSM8K 这两个数据集,测试的是语言模型解决数学问题的能力,而通过思维链提示,PaLM 这个大语言模型比传统提示学习的性能提高了 300%!在 MultiArith 和 GSM8K 上的表现提升巨大,甚至超过了有监督学习的最优表现。这意味着,大语言模型也可以解决那些需要精确的、分步骤计算的复杂数学问题了。
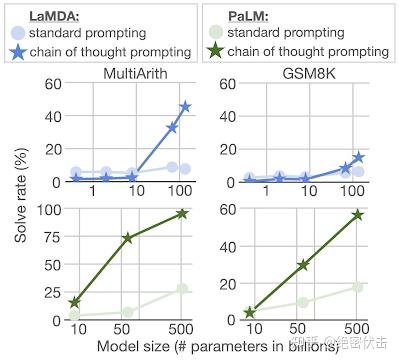
图1.2:数学逻辑推理大幅提升
- 大语言模型更具可解释性,更加可信。我们知道超大规模的无监督深度学习,打造出来的大模型是一个黑盒,推理决策链不可知,这就会让模型结果变得不够可信。而思维链将一个逻辑推理问题,分解成了多个步骤,来一步步进行,这样生成的结果就有着更加清晰的逻辑链路,提供了一定的可解释性,让人知道答案是怎么来的。Jason Wei 这位奇男子提出的思维链,可以说是大语言模型惊艳世界的必要条件。
CoT 的好处
自从 CoT 问世以来,CoT 的能力已经被无数工作所验证,如果对使用 CoT 的好处做一个总结,那么可以归纳为以下四点:
- 增强了大模型的推理能力:CoT 通过将复杂问题分解为多步骤的子问题,相当显著的增强了大模型的推理能力,也最大限度的降低了大模型忽视求解问题的“关键细节”的现象,使得计算资源总是被分配于求解问题的“核心步骤”;
- 增强了大模型的可解释性:对比向大模型输入一个问题大模型为我们仅仅输出一个答案,CoT 使得大模型通过向我们展示“做题过程”,使得我们可以更好的判断大模型在求解当前问题上究竟是如何工作的,同时“做题步骤”的输出,也为我们定位其中错误步骤提供了依据;
- 增强了大模型的可控性:通过让大模型一步一步输出步骤,我们通过这些步骤的呈现可以对大模型问题求解的过程施加更大的影响,避免大模型成为无法控制的“完全黑盒”;
- 增强了大模型的灵活性:仅仅添加一句“Let’s think step by step”,就可以在现有的各种不同的大模型中使用 CoT 方法,同时,CoT 赋予的大模型一步一步思考的能力不仅仅局限于“语言智能”,在科学应用,以及 AI Agent 的构建之中都有用武之地。
为了更加直观的展现出 CoT 对大模型能力带来的提升,论文作者在七个不同的推理任务数据集中对 CoT 的效果进行了实验,如下图所示,可以看到,相较于直接 Prompt, CoT 对所有的推理任务都带来了显著的提升。
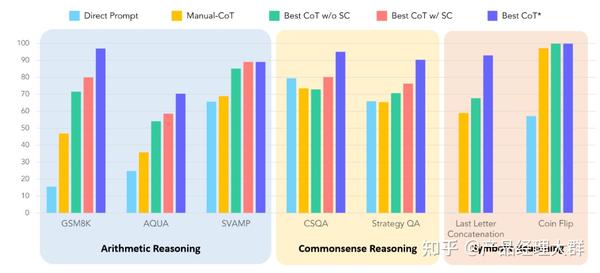
思维链效果如此拉满,那么 Jason Wei 提出的 CoT 到底是一项什么样的技术,接下来介绍下细节
3. CoT 生效的原理
关于 CoT 为什么会生效,目前尚且没有一套被大家广泛接受的普遍理论。但是,有许多论文对 CoT 与大模型的互动进行了一系列实验,类似物理实验与物理理论的关系,在实验中一些有意思的现象或许可以帮助我们理解 CoT 的工作原理:
- 模型规模小会导致 CoT 失效;
- 简单的任务 CoT 不会对模型性能带来提升;
- 训练数据内部彼此相互联结程度的增加可以提升 CoT 的性能;
- 示例中的错误,或者无效的推理步骤不会导致 CoT 性能的下降;
- ……

如果我们对这些现象做一些总结与延申,或许可以认为:首先,CoT 需要大模型具备一些方面“最基础”的知识,如果模型过小则会导致大模型无法理解最基本的“原子知识”,从而也无从谈起进行推理;其次,使用 CoT 可以为一些它理解到的基础知识之间搭起一座桥梁,使得已知信息形成一条“链条”,从而使得大模型不会中途跑偏;最后,CoT 的作用,或许在于强迫模型进行推理,而非教会模型如何完成推理,大模型在完成预训练后就已经具备了推理能力,而 CoT 只是向模型指定了一种输出格式,规范模型让模型逐步生成答案。
4. CoT技术细节
COT成果
在解释何为 CoT 前,不妨来看个论文展示的结果:
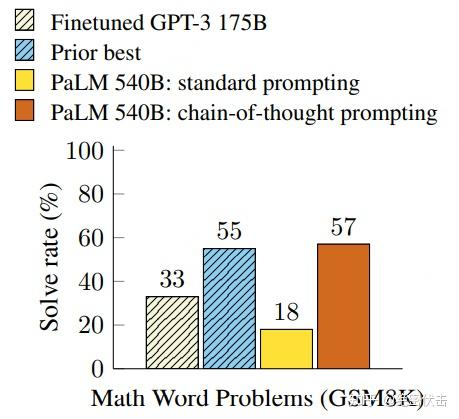
图1.3:CoT实验效果
不难看出,在解数学问题上,同样使用 PaLM 这个 540B 的超级 LLM,CoT 的表现是传统 prompting 的300%以上,甚至超过了此前有监督的最优表现。
这看起来很不可思议,然而 CoT 方法却极其简单。CoT 提示过程是一种最近开发的提示方法,它鼓励大语言模型解释其推理过程。思维链的主要思想是通过向大语言模型展示一些少量的 exapmles,在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。
以一个数学题为例:

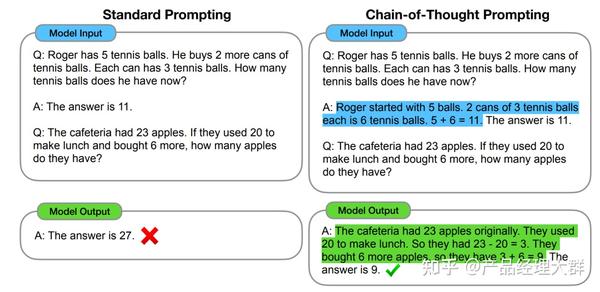
图1.4 标准 Prompting
可以看到模型无法做出正确的回答。但如果说,我们给模型一些关于解题的思路,就像我们数学考试,都会把解题过程写出来再最终得出答案,不然无法得分。CoT 做的就是这件事,示例如下:

图1.5:CoT提示
可以看到,类似的算术题,思维链提示会在给出答案之前,还会自动给出推理步骤:
“罗杰先有5个球,2盒3个网球等于6个,5 + 6 = 11” “食堂原来有23个苹果,用了20个,23-20=3;又买了6个苹果,3+6=9”
可以看出,CoT 在实现上修改了 demonstration 每个 example 的 target,source 保留原样,但 target 从原先的 answer(a) 换成了 rationale(r) + a。因此可以看到右侧,所有内容均由模型生成,模型不是生成 a,而是生成r+a。
简单来说,语言模型很难将所有的语义直接转化为一个方程,因为这是一个更加复杂的思考过程,但可以通过中间步骤,来更好地推理问题的每个部分。
标准的prompt让大模型直接做数学题,果然大模型一问一个胡说八道,证明它确实没有推理能力。思维链则在one-shot(啥是zero/few shot )当中加入了解题的中间过程,诱导大模型“按步骤解题”,不是直接给出计算结果,这一回大模型终于推导出了正确的答案。
思维链提示
思维链提示,就是把一个多步骤推理问题,分解成很多个中间步骤,分配给更多的计算量,生成更多的 token,再把这些答案拼接在一起进行求解。
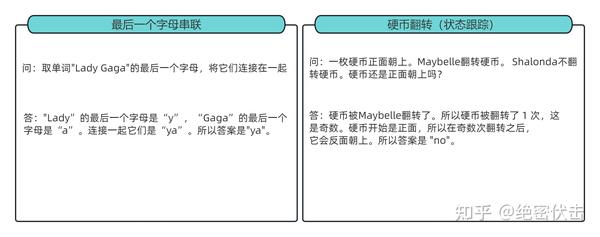
论文里面作者提到了很多 CoT 的优势,其中包括它把一个多步推理问题分解出多个中间步骤,并且让 LLM 更加可解释。它能解决的问题很多,除了上述的数学应用题,还有常识推理、以及 symbolic manipulation (符号操作)这类任务(就是一些手造的考验大模型的问题,比如最典型的 Last Letter Concatenation(最后一个字母串联) 和 coin flip(抛硬币)),下面补充几个例子方便理解:
关于何时应该使用 CoT 事实上还是一个开放问题,但是这篇论文从“工程”与“理论”两个角度为我们带来了一些 CoT 适用场景的洞见。
首先,从工程的角度而言,CoT 的适用场景抽象一下可以被归纳为三点,分别是使用大模型(1),任务需要复杂推理(2),参数量的增加无法使得模型性能显著提升(3)。此外,现有的论文实验也表明,CoT 更加适合复杂的推理任务,比如计算或编程,不太适用于简单的单项选择、序列标记等任务之中,并且 CoT 并不适用于那些参数量较小的模型(20B以下),在小模型中使用 CoT 非常有可能会造成机器幻觉等等问题。
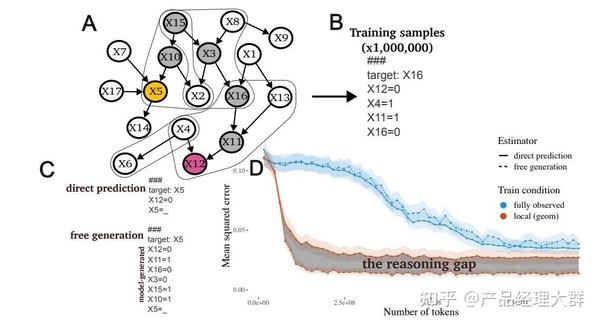
而从理论角度,一篇来自斯坦福的论文《Why think step-by-step? reasoning emerges from the locality of experience》揭示了当大模型的训练数据表现出了如上图中的变量的局部簇结构(Local Clusters of Variables)时,CoT 将会展现极好的效果。而变量的局部簇主要指训练数据中变量之间有着强的相互作用,相互影响的关系。
此外,也有研究指出,当给予大模型的示例之间彼此之间互相区分并不相同时,也有助于提升 CoT 的性能。同时,逻辑依据是否与问题相关,逻辑推理步骤的顺序也会显著影响 CoT 的性能。另外一个有趣的发现是,使用代码数据训练大模型,或者使用符合 CoT 格式的数据训练模型也有助于提升 CoT 的性能。总结一下:
CoT 应当被用于 20B 以上参数规模的模型之中,并且模型的训练数据应当于任务问题相关且彼此相互有较强的联结。
COT构造
1、人工构造:质量高,但人力成本大,不好优化、不好跨任务迁移
2、自动构造:分为 Zero-shot CoT 和 Auto CoT 两种方式。前者通过特定的提示文本激发模型在没有示例的情况下生成推理链条;后者则是使用前者零样本生成的推理链条,并结合示例选择策略,通过少样本学习的方式生成推理链条。但自动的质量一般没有人工的好,导致大模型幻觉问题严重。
5. CoT 朝着什么方向发展?
在这 CoT 问世的一年多以来,CoT 也开始从最简单的“Let’s think step by step”慢慢进化,作为一篇综述,这篇论文也相当全面的概括了 CoT 的发展方向与进化路径,如果我们需要按图索骥 CoT 的现有文献,可以从下面这张图出发:
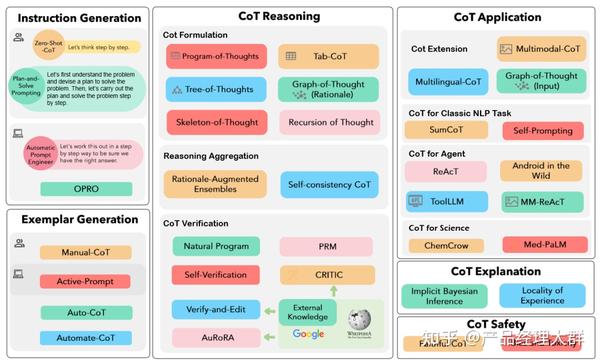
总的来说,CoT 的发展方向有三条主要的路径,如图从左到右分别是 “Prompt 模式”,“推理结构”以及“应用场景”。从这三个主要的发展方向出发,我们来概述一下主要的论文:
Prompt 模式
首先,是 Prompt 模式,在上图中的最左边,Prompt 模式主要研究“向大模型输入怎样的 Prompt 可以使得大模型获得更好的推理能力”,关于 Prompt 模式的研究也可以分为两类,分别是指令生成与范例生成。
对于指令生成问题,又可以分为手动指令生成与自动指令生成,显然简单的“Let’s think step by step”就属于手动指令生成模式,此外,另一类的手动指令生成模式是 Plan-and-Solve 方法,其主要思想在于让模型制定一个将任务分为更小子任务的计划,再让模型一步一步执行计划、解决问题,其 Prompt 为“Let’s first understand the problem and devise a plan to solve the problem. Then, let’s carry out the plan and solve the problem step by step”。
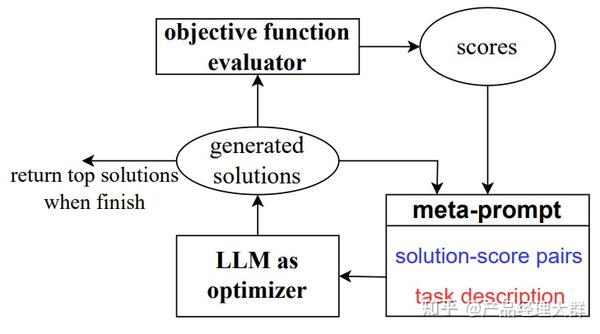
显然,手动指令生成无法适应复杂的实际情况,因此自动指令生成应运而生,自动指令生成的代表作有两个,分别是自动 Prompt 工程(APE)以及提示优化(OPRO),如上图所示,APE 与 OPRO 的核心思想都在于设计了一套机制让大模型通过观察各个候选的 Prompt 的实际任务中的表现,通过最大化表现得分来自动选择最优的 Prompt 。
类似的,范例生成也可以分为手动范例生成与自动范例生成,传统的 Few-Shot-CoT 就是一种典型的手动范例生成方法,在 Few-Shot-CoT 的基础上,一种让大模型使用手动生成的范例多次回答问题,再从其中依据如熵、方差等的不确定性度量选择“最不确定”的问题,通过手动注释来加强范例生成的 ActivePrompt 方法诞生,成为了一种介于手动范例生成与自动范例生成之间的范例生成方法。而为了将范例生成完全“自动化”,Auto-CoT 方法被提出,具体而言,Auto-CoT 分为两个阶段:(1)问题聚类,对任务数据集进行聚类(2)示例采样:从每个聚类中心中选择一个代表性问题使用 Zero-Shot-CoT 生成思维链作为示例。
推理结构
除了研究“什么样的 Prompt 会诱导出更好的 CoT 能力以外”,还有很大一部分研究者关注于 CoT 本身的结构问题,主要的研究思路包含 “CoT 构造”、“推理聚合”以及 “CoT 验证”。
CoT 构造主要将传统线形,链式的 CoT 转化为如表格、树状、图状格式,代表工作有非常出名的 PoT,Tab-CoT,ToT 以及 GoT-Rationale,下面这张图非常清晰的展示了这四种方法的异同:
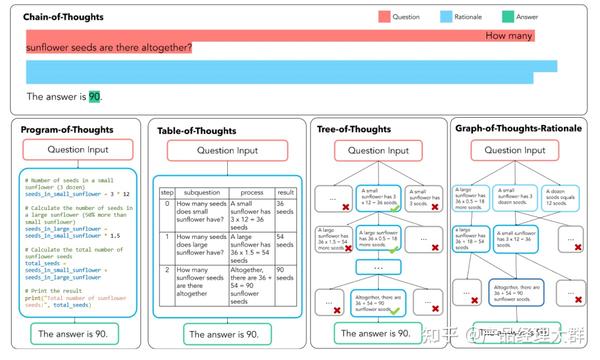
首先是 PoT,其中 P 指 Programm 即程序,PoT 的思想也非常简单,对思维链中大模型有可能出错的一些计算问题,让大模型生成出编程语言在解释器中运行,以将复杂计算与模型的文本生成解耦。
其次是 Tab-CoT,其中 Tab 指 Tabular 表格,在 ToT 中,研究者迫使大模型在每一步的推理中记录一个“∣步数∣子问题∣过程∣结果∣”的推理表格,并让大模型在推理时从生成的表格中提取答案,从而增强大模型的推理能力。
此外,就是 ToT,其中 T 指 Tree 即思维树,简单理解就是将 CoT 的链式结构扩展为树形结构。ToT 让大模型在解决子问题时生成多个不同的答案选择,通过此建立的树形结构让大模型可以展望未来确定下一步的决策并且通过追溯来纠正历史决策。
基于 ToT 的思想,将 Tree 拓展为 Graph,就形成了 GoT。GoT 系统的核心在于一个“控制器”,控制器处理对图的操作(GoO)以及图状态推理(GRS),其中 GoO 用于将一个给定的任务进行图分解,将一个任务分解为相互连接的节点-边关系,而 GRS 则负责维护大模型在 GoO 生成的图上的推理过程,记录当前步的状态,决策历史等等信息。
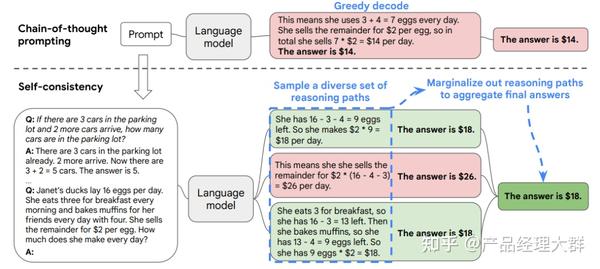
除了各种 XoT 以外,对于推理过程的“解码”问题,也有一些工作进行了研究。其中,推理聚合的代表性工作是 Self-consistency CoT。Self-consistency CoT 使用手动设计的 Prompt 生成采样一组不同的推理路径,再通过“多数投票”找到推理步骤中“最一致”的路径,使用这条解码路径驱动原始的贪心解码方式来提示 CoT 性能。
最后,在针对推理结构的研究,还有一类是 CoT 验证,CoT 验证开始侧重于通过多轮提问,让大模型进行“自我验证”,在前向后向的反复问答中让大模型可以验证自己的回答,而伴随着 CoT 验证的发展,也有工作开始引入“外部工具”对 CoT 中的信息进行验证,例如信息检索、计算器、计算机程序等等。

CoT 验证最经典的工作即是自我验证(Self-Verification),自我验证有两个步骤,分别是(1)对多个候选的推理路径进行采样;(2)给定问题结论让大模型验证条件是否满足结论,并根据验证分数对候选结论进行排序。
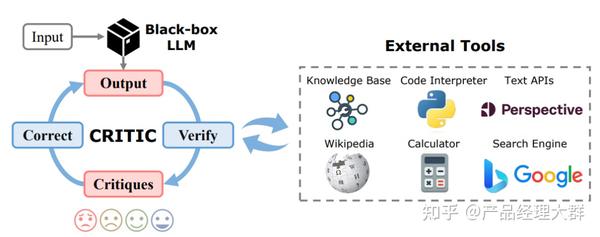
而引入外部工具的 CoT 验证的代表性工作譬如 CRITIC 框架,CRITIC 使得大模型可以交互式的引入外部工具来验证与修改自己的答案输出,经过大模型输出,外部工具验证,验证结果反馈,反馈修改四个循环的步骤加强 CoT 输出的可靠性。而将 CRITIC 的思想进一步推向机制,即出现了任务自适应与流程自动化的 AuRoRA,AuRoRA 从多个来源提取相关知识,将不同来源的知识进行组合、检查与提炼来修改初始 CoT,以提示 CoT 的准确性与逻辑性。
比较有意思的一点在于,在论文《Can large language models really improve by selfcritiquing their own plans?》中,作者质疑了大模型是否可以真的进行可靠的 CoT 验证,在大模型的能力本身“无法解决验证结果反馈提出的问题”时,大模型有可能会过度纠正推理过程,直接跳过正确答案。
应用场景
除了对 CoT 本身的改变,还有许多工作将 CoT “部署”于不同的应用场景之下以提升各种场景下大模型的能力,譬如最简单的从单语言 CoT 扩展到多语言 CoT。这些应用场景包括从单模态到多模态以及从复杂推理任务到通用推理任务的扩展。其中,多模态 CoT 具有很大的应用前景,在 CoT 中,多模态可以分为两类:输入多模态与输出多模态。
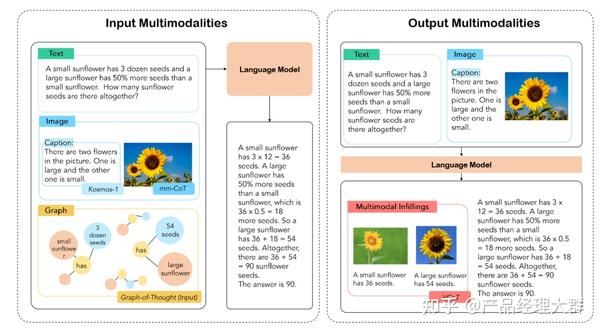
其中,MM-CoT 是输入多模态研究的第一篇工作,MM-CoT 侧重使用微调方法嵌入 CoT,通过将语言和图像合并在一个包含推理生成与答案推理的两阶段的框架中,使用微调大模型赋予输入多模态 CoT 的能力。基于 MM-CoT,GoT-Input 方法通过对 CoT 生成的思维图进行抽取构建三元组,并使用 GNN 将文本、图像与 CoT 统一,从而生成包含 CoT 信息的最终答案。而区别于输入多模型,VCoT 解决了一个输出多模态的问题,VCoT 通过以生成图片的“标题”以及识别核心关注点作为图像生成的启动过程,通过递归的方式填充图像信息,从而实现输出多模态。
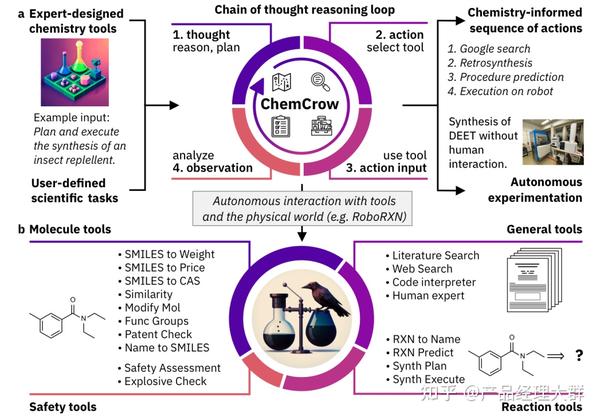
除了多模态 CoT 以外,CoT 目前也已经用于如文本摘要(SumCoT),开放域问答(Self-Prompting LLMs),机器翻译(MAPS),化学(ChemCrow)、医学(Med-PaLM)等等领域
6. CoT 与 AI Agent 有何关系?
回忆我们上一篇中介绍的关于 Agent 的定义,我们期望通过各种AI 技术构建的 Agent 事实上是一类拥有“自主智能的实体”,可以自主的发现问题、确定目标、构想方案、选择方案、执行方案、检查更新。基于大模型解决问题的“通用性”与预训练得到的“先天知识”,构建的大模型智能体可以被认为具有如下图的结构:
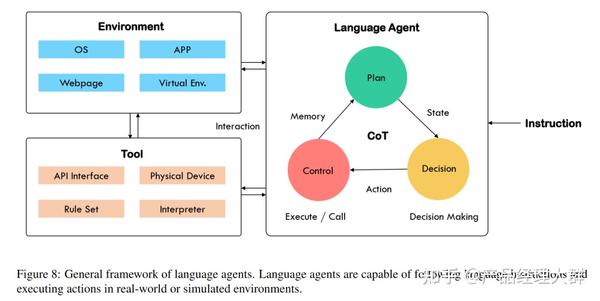
上图中大模型智能体主要由三部分组成,分别是 Agent 主体,工具与环境。当人类指令输入 Agent 主体后,Agent 主体通过一系列计划、决策与控制,使用工具与外部环境互动。
其中显然,作为 Agent 主体的大模型是模拟人类智能决策流程的核心,在许多 Agent 需要处理的任务中,Agent 的“先天知识”并不包含解决任务的直接答案,因此 Agent 需要在一系列与外部环境的交互循环中,制定计划,做出决策,执行行动,收到反馈……在一整个计划、决策与控制的循环中,大模型需要具备“感知”,“记忆”与“推理”的能力,如下图所示, CoT 恰恰可以从这三个方面来“赋能” Agent。
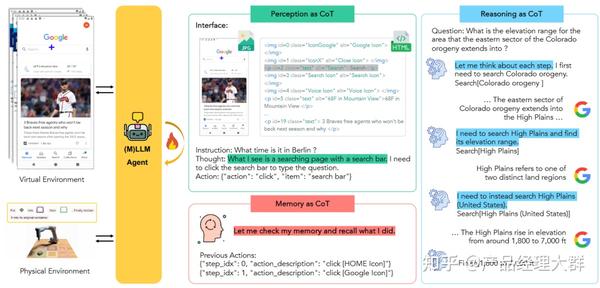
感知 CoT
无论是环境的反馈,还是人类的指令,Agent 都需要完成一个对接收到的信息进行“理解”,并依据得到的理解进行意图识别,转化为下一步任务的过程。而使用 CoT 可以大大帮助模型对现有输入进行“感知”,譬如,通过使用“Answer: Let’s think step by step. I see $$, I need to …”的 Prompt,可以让模型逐步关注接收到的信息,对信息进行更好的理解,再如,在机器人控制的场景下,Agent 的决策不可避免的会出现错误,而接受到错误信息的反馈让 Agent 理解错误的原因调整自己的行动也是 Agent 应用于动态场景下的多轮决策任务中的关键能力,感知 CoT 也将加强模型自我纠错的能力。
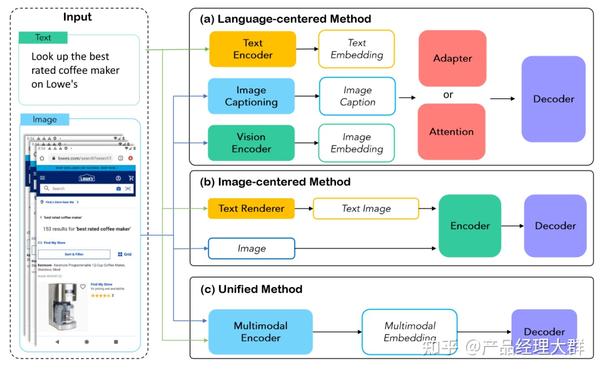
此外,值得注意的是,与外部环境的互动需要 Agent 具有处理多模态信息的能力,这种能力要么需要 Agent 本身是一个多模态的大模型,要么需要 Agent 可以将其他模特信息转化为语言进行理解。其中一个非常有意思的问题是“是否大模型 Agent 只能存在以语言为中心的感知?”,如上图所示,事实上有许多工作不仅在以语言为中心的感知中拓展大模型编码其他模态信息的能力,并且也发展出了譬如以图像为中心的感知方法,与将文本与图像进行统一的真正以多模态为中心的感知方法。但是由于多模态信息带来的数据、计算、可扩展性等方面的种种问题,真正以多模态信息为中心的感知时代暂且还未到来。
记忆 CoT
一般而言,大模型智能体通常同时拥有短期记忆与长期记忆的能力。短期记忆一般作为一种时间信息,可以在 Agent 的多轮交互中灵活的改变(因此也被称为工作记忆),短期记忆为大模型提供更加直接的上下文信息支持,因此很自然的可以被建模为一条历史动作链。
相比于短期记忆的“动态性”,长期记忆更多的提供历史事件中的静态信息的记录,是对历史知识更加宏观与抽象的理解,长期记忆可以依赖于大模型中的可训练参数进行构建,也可以通过外部维护的记忆库进行构建。
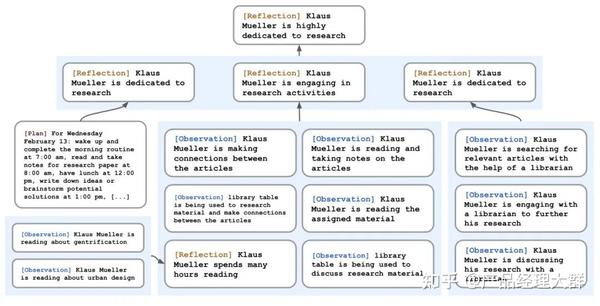
而当序列长度变长,线性链条式的记忆链效率出现下降时,为了实现针对“记忆”高效的增删改查,一些工作探索了树搜索与矢量检索的方法。
其中,树搜索将记忆信息以树结构进行存储,让智能体通过迭代访问文本记忆信息,譬如斯坦福 25 人小镇论文中提出的反思树 Reflection Tree,当智能体面对与环境的多轮交互时,反思树可以让智能体定期抽取历史信息进行“反思”,将反思抽象得到的结果搭建构成一颗反思树,树的叶子节点代表大模型每轮的基本观察,而非叶子节点则代表反思树的抽象程度,越靠近根节点抽象程度越高。
而另一种方法则是矢量检索,通过将复杂数据类型建模为矢量数据库来实现长期记忆的高效存储与检索,当智能体遇到新问题需要“回忆”过往记忆时,基于矢量数据库的长期记忆系统则会快速检索相关信息,确保智能体行为一致性。
推理 CoT
除了感知与记忆,借鉴 CoT 的思路让智能体分解任务逐步进行计划与决策以增强智能体解决问题的可靠性。在 Agent 中,CoT 主要的功能在于将计划、行动与观察相互结合,弥合推理与行动之间的差距,显然,推理可以帮助模型制定行动计划处理异常情况,而行动则允许大模型在与外部环境进行交互的同时,收集附加信息支持模型的推理。
譬如,AgentBench 强迫大模型智能体通过“思考”+“行动”步骤完成任务,而行动链技术通过一系列行动历史与未来行动计划帮助智能体进行决策,从而将决策问题转化为 CoT 推理问题。
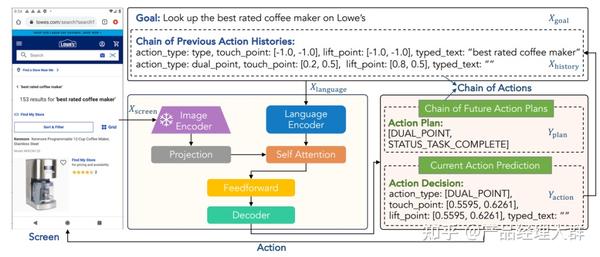
此外,工具的使用扩展了大模型 Agent 的能力边界,通过使用工具,大模型不再局限于“预测”下一步的动作,而获得了“实际执行”动作的能力,譬如输出代码操作机器,调用 API 获得数据,使用各种软件、计算工具等等,同时,使用浏览器获取“实时更新”的“新知识”作为大模型的检索增强也有效的扩展了大模型的知识边界,也为大模型“自我验证”提供了知识库。而除了使用工具以外,类似编写“教科书”,现在还有一些研究关注在“专门针对 Agent 任务场景”的数据集上对大模型进行微调以获得更强的 Agent。
7. CoT的局限性
前面说了这么多,是不是有了思维链,大语言模型就所向披靡了呢?照这么发展下去,真能媲美人类的能力了?
大可不必担心,思维链本身还是有很多局限的,而它的局限也是大语言模型的局限。
首先,思维链必须在模型规模足够大时才能涌现。
在 Jason Wei 等的研究中,PaLM 在扩展到 540B 参数时,与思维链提示结合,才表现出了先进的性能。一些小规模模型,思维链并没有太大的影响,能力提升也不会很大。
谷歌大脑的研究人员认为,策略问题需要大量的世界知识,而小型模型没有足够的参数来记忆这些世界知识,所以也不太可能产生正确的推理步骤。
但问题是,能落地到产业的模型,规模必然不会太大,思维链拆解了更多的步骤、用到更多的计算资源,相当于更加耗费脑力,很多研究机构和企业是负担不起 175B 参数以上的大模型。
所以思维链必须要探索,如何在较小的模型中进行推理,降低实际应用的成本。
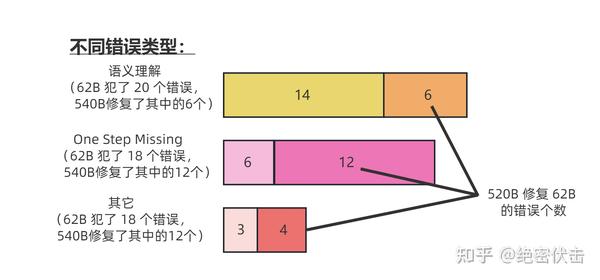
图7.1:62B 比 540B 的语言模型更容易出错
其次,思维链的应用领域是有限的。
目前,思维链只是在一些有限的领域,比如数学问题,五个常识推理基准(CommonsenseQA,StrategyQA,Date Understanding 和 Sports Understanding 以及 SayCan)上显现出作用,其他类型的任务,像是机器翻译,性能提升效果还有待评估。
而且,相关研究用到的模型(GPT-3 API)或数据集,都是半公开或不公开的,这就使其难以被复现和验证。严谨来看,思维链的效果还需要被进一步探索,才能下定论。
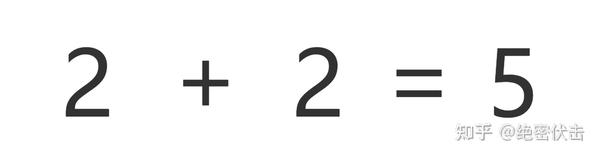
图7.2:即使有思维链提示,大语言模型依然不能解决小学水平的数学问题
此外,即使有思维链提示,大语言模型依然不能解决小学水平的数学问题。
没有思维链,数学推理是指定不行。但有了思维链,大语言模型也可能出现错误推理,尤其是非常简单的计算错误。Jason Wei 等的论文中,曾展示过在 GSM8K 的一个子集中,大语言模型出现了 8% 的计算错误,比如6 * 13 = 68(正确答案是78)。
这说明,即使有了思维链,大语言模型还是没有真正理解数学逻辑,不知道加减乘除的真实意义,只是通过更精细的叠加来“照葫芦画瓢”,所以,对于有精确要求的任务,还要进一步探索新的技术。
思维链确实增强了大语言模型的能力,但逻辑推理仍然是大语言模型的弱项,等待着更多突破。
One more thing
通过思维链,我们可以看到大语言模型为什么强,也为什么弱。
它强在,模型规模的提高,让语义理解、符号映射、连贯文本生成等能力跃升,从而让多步骤推理的思维链成为可能,带来“智能涌现”。
它弱在,即使大语言模型表现出了前所未有的能力,但思维链暴露了它,依然是鹦鹉学舌,而非真的产生了意识。
认知心理学教授斯坦尼斯拉斯·迪昂(Stanislas Dehaene)在《精准学习》中提出,缓慢地、理智地、符号化地运作,是人脑的特权。它可以在任何可能的时候,提取具有普遍性、逻辑性的、明确的原则。
五六岁的儿童学会了较小数字的加法,就可以理解其含义,用到更大的数字的加法中,而目前最强大的大语言模型,还连“加法”这个简单的抽象定律都理解不了。
大语言模型,正如科幻作家特德·姜所说,是网上所有文本的模糊图像,一张有损压缩的 JPEG,但它可以用远超人脑的算力和数据,极其高产地做好文本生成、图像生成这样的模糊任务。而人脑更擅长精确的、逻辑性的任务,就像特德·姜说的:“当你还有原始图片的时候,一张模糊的 JPEG 到底有多大用处呢?”
智能时代的生存策略,就是不要以己之短,硬碰 AI 之长。而是用 AI 之长,让自己的长板变得更长;用人脑的精确,让 AI 生成的模糊答案变得更高质量;用好思维链提示,让 LLM 生成时事半功倍。
8.目前 CoT 与 AI Agent 还面临哪些挑战?
尽管,当下 CoT 与 AI Agent 已经在编程、科研、办公等等领域得到了极其广泛的应用,但是作为一个新兴领域,无论是CoT 还是 AI Agent 都面临着许多的落地挑战,其中包括:
- 在未知领域中的泛化能力:尽管 AI Agent 的出现本身就拓展了大模型解决更加复杂未知领域问题的能力,但是由于缺乏与现实世界真正“具身”的交互,因此一个可以做到浏览网页的 Agent 是否通过同一套框架与工程手段就可以做到操控无人机编组,这一问题仍然悬而未决;
- Agent 的过度交互问题:为了完成任务,Agent 需要与环境进行大量复杂多步的交互,而一些研究也表明 Agent 很有可能会陷入到不断交互的循环陷井之中,在交互循环中无意义的空转,并且,由于 Agent 解决问题缺乏“效率”,因此由此生出的日志的存储与信息检索也将成为新的问题;
- 个性化 Agent:人手一个的私人智能助理是一个美好的畅想但是一个真正的个性化 Agent 的实现还面临许多问题,目前个性化 Agent 的研究有三条技术进路,分别是从定制化的 Prompt 出发,从微调出发以及从模型编辑出发,但是这些进路都有各自的问题,并且当下研究都主要聚焦于特定的问题背景,目前还不存在一套完整统一的解决方案;
- 多智能体社会:如何扩大大模型 Agent 的数量,以组成一个多智能体的社会用于观察“社会行为的涌现”也是一个非常有意思的方向,但是多智能体的计算开销是阻碍这一领域发展的关键问题;
- Agent 安全问题:当 Agent 逐步进入人们的日常生活,Agent 与 CoT 的安全性问题就必须得提上日程,譬如老生常谈得隐私泄露、权限滥用、有毒信息等等问题,此外,当 Agent 应用于现实世界后,此外,由于缺少现实世界真正多模态的反馈,譬如人类智能可以感受到“痛”,而 AI Agent 不会有这方面的信息输入,因此如何对完全不同质的两类主体进行“对齐”也将是关键问题;
- Agent 的评价:如何客观的评估一个 Agent 的能力也将是 AI Agent 发展带给我们的新问题,想想几年前 NLP 时代的数据集刷榜的评估方式,这种传统评价方式必然不适用于一个不断与外部环境打交道的 Agent。此外,一个做对了 99 步但生成答案错误的智能体可以本身能力要优于一个做错了 99 步但生成答案正确的智能体,因此 Agent 评价也呼唤除了评估执行任务的成功率以外的新指标、新方法。
总结
本篇文章主要是介绍了 CoT 以及后续的改进,目前从推特上观察,CoT已经被广泛应用,甚至很多人认为就是标准的做法。但国内来看,似乎缺乏对它的重视,觉得不过是个简单的 trick。其实不只是 CoT,对整体 LLM 的认知和谷歌、OpenAI 那边确实有些差距。至于为何,Jason Wei 那条推特一定程度说明问题,知乎上也有人把他删掉的推特截图放出来,大致意思是20年后入门 NLP 的人比之前的幸福,他们对 LM 的认知来自于强大的 LLM,而过去的人往往还停留在 BERT 的范式。
参考
大模型思维链(Chain-of-Thought)技术原理 – 知乎 (zhihu.com)
从 CoT 到 Agent,最全综述来了!上交出品 – 知乎 (zhihu.com)
https://zhuanlan.zhihu.com/p/657737603?utm_psn=1716386289283362816
https://zhuanlan.zhihu.com/p/655427670?utm_psn=1716386167392411648